
In diesem Beitrag trainieren wir einen Bildklassifizierer, der es ermöglicht, Bilder einer bestimmten Klasse zuzuordnen. Ein simples Beispiel dafür ist die Zuordnung von Bildern, auf denen Obst abgebildet ist, zu den Klassen: Apfel, Birne, Banane, Orange, Kiwi und so weiter. Auch in der Produktion kann Bildklassifizierung nützlich sein. Ein KI-Modell zur Klassifizierung kann beispielsweise genutzt werden, um zu beurteilen, ob ein Fräser noch arbeitsscharf ist oder schon verschlissen. Was Sie dafür brauchen? Beispielbilder, die die Klassen entsprechend repräsentieren. Den Rest erklären wir Ihnen Schritt für Schritt:
- Datenverarbeitung
- Erstellung des künstlichen neuronalen Netzes
- Training des künstlichen neuronalen Netzes
- Ausführung des künstlichen neuronalen Netzes
1. Datenverarbeitung
Fangen wir an: Als erstes importieren wir die notwendigen Software-Bibliotheken. Diese ermöglichen es, auf vorhandene Funktionen zurückzugreifen und so mit wenigen Zeilen Code eigentlich aufwendige Programme zu schreiben. Die wichtigste Bibliothek, die wir heute verwenden, ist PyTorch. Sie wird mit dem Befehl import torch importiert. Außerdem importieren wir noch Torchvision, da wir Bilder verarbeiten wollen.
Die weiteren Bibliotheken sind Standardbibliotheken, die nahezu in jedem Python-Programm genutzt werden. Numpy wird beispielsweise zum Berechnen von Matrizen genutzt und Matplotlib, um Diagramme orientiert am Programmierstil von Matlab zu erstellen.
import torch
import torchvision
import torchvision.transforms as transforms
import pathlib
import PIL
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imreadIm Anschluss prüfen wir, ob wir das künstliche neuronale Netz (KNN) auf der Grafikkarte (GPU) des Computers ausführen können. Hierdurch lässt sich eine deutliche Steigerung der Performance erzielen.
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)Nun geben wir den Pfad des Datensatzes an und transformieren die Daten für die weitere Verarbeitung. Die Funktion transforms.Compose ermöglicht dabei eine Vielzahl an Transformationen. Wichtig ist auch die Funktion transforms.ToTensor(). Mit dieser werden die Bilddaten in einen PyTorch-Tensor, eine Art Matrix, konvertiert. Außerdem geben wir die Batch-Size an. Diese beschreibt, wie viele Bilder das neuronale Netz beim späteren Training verarbeitet, bevor die Gewichte angepasst werden. Zum Schluss wird der Datensatz erzeugt.
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
transforms.Resize(32, antialias=None)]) #Die Bilder werden bspw. auf 32 Pixel reduziert
batch_size = 4
dataset_path = "/.../.../" #Pfad zum Datensatz
dataset = torchvision.datasets.ImageFolder(root=dataset_path, transform=transform)Aber wie müssen die Daten abgelegt werden? Im Fall der Klassifizierung werden die Daten entsprechend ihrer Klasse abgelegt. Wollen wir beispielsweise Äpfel und Birnen klassifizieren, enthält ein Order alle Bilder von Äpfeln und ein Ordner alle Bilder von Birnen. Beide Ordner sind im Datensatzpfad abgelegt. In diesem Fall heißt der Ordner zum Beispiel „Obst“. Wir geben dann den Pfad zu diesem Ordner an.
/Users/...../Daten/Obst/Nun teilen wir den Datensatz in drei Teile. Der erste Teil wird für das Training verwendet. Er umfasst den größten Prozentanteil des Datensatzes. An ihm lernt das künstliche neuronale Netz die einzelnen Merkmale, die eine Unterscheidung in die einzelnen Klassen ermöglicht. Der zweite Teil wird zur Validierung während des Trainings genutzt. So stellen wir sicher, dass das KNN nicht zu spezifische Merkmale die nur im Trainingsdatensatz vorhanden sind, erlernt. Hierbei spricht man von „Overfitting“.
Anpassung des Modells
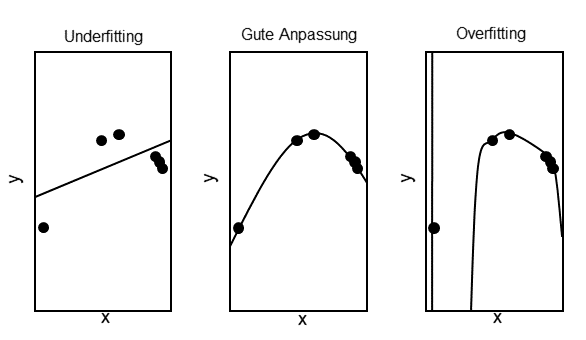
Der letzte Datensatz wird teilweise nicht erstellt/verwendet. Er wird für den finalen Test des trainierten Modells verwendet. Dieser kann notwendig sein, wenn beispielsweise Parameter in Abhängigkeit vom Ergebnis des Validierungsdatensatzes während des Trainingsprozesses angepasst werden. Gängig ist beispielsweise die Anpassung der Lernrate. Der Testdatensatz stellt somit sicher, dass das Modell auch auf komplett unbekannten Daten gute Ergebnisse erzielt.
trainset, valset, testset = torch.utils.data.random_split(dataset, [0.8,0.1,0.1]) # 80 % Training, 10 % Validierung , 10 % Test
print('Länge Testset: ',len(trainset))
print('Länge Testset: ',len(valset))
print('Länge Testset: ',len(testset))
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
valloader = torch.utils.data.DataLoader(valset, batch_size=batch_size,
shuffle=False, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('Apfel', 'Birne', 'Kirsche')2. Erstellung des künstlichen neuronalen Netzes
Jetzt erstellen wir unser neuronales Netz. Dafür werden in der Regel vorab definierte Netzarchitekturen verwendet. Auf die einzelnen Bestandteile gehen wir nicht näher ein, da dieser Schritt hier entfällt.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # in_channels, out_channels, kernel_size
self.pool = nn.MaxPool2d(2, 2) # kernel_size, stride
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # in_features, out_features
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # Max-Pooling definiert in der __init__ Methode
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x)) # Relu Funktion wird Elementweise angewendet.
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
## Die Backward Methode muss nicht definiert werden, da wir torch.nn verwenden und hier die Backward Methode automatisch erstellt wird.
net = Net()
net = net.to(device) # Hier wird das entsprechende Gerät von weiter oben verwendetEbenfalls in PyTorch enthalten sind verschiedene Kosten- und Optimierungsfunktionen. Je nach vorliegender Problemstellung kann es hilfreich sein, diese zu variieren. Für unser Beispiel verwenden wir Cross-Entropy für die Kostenfunktion und einen SGD-Optimierer.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)3. Training des künstlichen neuronalen Netzes
Nun haben wir alle Bestandteile, um ein KI-Modell zu trainieren. Wir haben die Daten, diese wurden entsprechend vorverarbeitet und in einen Trainings-, Validierungs-, und Testdatensatz unterteilt. Wir haben das KNN und wir haben die Werkzeuge, um das Training zu steuern. Im Training werden nun alle Trainingsbilder dem KNN in Batches, als kleine Sammlungen von Bildern, präsentiert. Die Batch-Size, die wir bereits festgelegt haben, gibt dabei an, wie viele Bilder dem Netz übergeben werden, bevor die Parameter des Netzes angepasst werden.
for epoch in range(2): # 2 Epochen werden gewaehlt
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# Trainingsschritte: Vorwaerts- + Rueckwerts- + Optimierungsschritt
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # Alle 2000 Batches wird das Ergebnis der Kostenfunktion ausgegeben
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Training beendet')In unserem Beispiel wurde das KNN nun zwei Epochen trainiert. Das heißt, dass zweimal hintereinander alle Trainingsbilder dem KNN übergeben wurden. An einigen Stellen liest man auch von Iterationen. Die Anzahl an Iterationen errechnet sich durch die Anzahl an Trainingsbildern geteilt durch die Batch-Size. Haben wir 1.024 Bilder und eine Batch-Size von 4 werden 256 Iterationen für eine Epoche benötigt.
Anmerkungen:
-
- Gewöhnlich ist die Epochenanzahl deutlich höher. Für den Start und um schnell Ergebnisse zu sehen, können wir aber auch die geringere Zahl verwenden. Die Erkennung wird dadurch vermutlich etwas schlechter als bei einer höheren Anzahl an Epochen. Die Epochenanzahl wird aber auch durch die Qualität und Größe des Datensatzes beeinflusst.
-
- Wir haben in diesem Trainingsbeispiel nicht den Validierungsdatensatz verwendet. Für diese Beitrag haben wir es bei einem einfacheren Training belassen.
Um das Training nicht jedes Mal wiederholen zu müssen, wenn wir das Modell verwenden, speichern wir das KNN ab.
PATH = '../../name_des_KNN.pth'
torch.save(net.state_dict(), PATH)4. Ausführung des künstlichen neuronalen Netzes
Nun können wir das Modell jederzeit laden und verwenden. Hierfür benutzen wir:
net = Net()
net.load_state_dict(torch.load(PATH))Jetzt wollen wir das Modell noch testen. Dafür nehmen wir einige Bilder aus dem Testdatensatz und lassen vom Modell die Klasse ausgeben. Als Referenz betrachten wir die Label. Der Nachfolgende Code-Block sorgt zunächst dafür, dass die ausgewählten Bilder sowie die dazugehörigen Label angegezeigt werden.
dataiter = iter(testloader)
images, labels = next(dataiter)
# zeigt die Bilder an
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join(f'{classes[labels[j]]:5s}' for j in range(4)))Im Anschluss wird die Vorhersage des Modells ausgeben.
outputs = net(images)Außerdem können wir uns noch die Genauigkeit (Accuarcy) des gesamten Modells angucken. Diese beschriebt in Prozent, wie viele Bilder korrekt kategorisiert wurden.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
# An dieser Stelle wird die Ausgabe des Netzes berechnet
outputs = net(images)
# Das Netz gibt Klassen und einen Wert fuer die Konfidenz aus
# Die Klasse mit der hoechsten Konfidenz wird ausgewaehlt
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy des Netzes: {100 * correct // total} %')Wenn Sie die Anleitung Schritt für Schritt durchgegangen sind, haben Sie Ihren Bildklassifizierer für die Nutzung in Ihrer Produktionsumgebung trainiert. Bestehen noch Fragen zu den einzelnen Schritten? Melden Sie sich bei Ihrem Ansprechpartner Paul Krombach.
Quellen:
https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
https://www.kaggle.com/code/rzatemizel/100-accuracy-explainability-with-grad-cam-lime




