You only look once (YOLO) ist eine beliebte Netzarchitektur für die Klassifizierung, Objekterkennung und Segmentierung in Echtzeit. Mit YOLO kann beispielsweise bei der automatisierten Qualitätskontrolle mittels Klassifizierung bestimmt werden, ob sich Kratzer auf einem Bauteil befinden. Bei der Objekterkennung wird das Objekt mit einer Bounding Box markiert, so kann auch die Anzahl und die Größe der Kratzer angegeben werden. Eine Alternative dazu ist die Segmentierung. Bei dieser wird die Position eines Kratzers pixelgenau bestimmt. Der Aufwand der Datenvorbereitung für das Training eines solchen KI-Modells ist allerdings auch wesentlich größer. Die Unterschiede zwischen den Verfahren sind oben im Beitragsbild dargestellt.
Welche Hardware verwende ich für die Objekterkennung mit KI?
Wie bereite ich die Daten für das Training meines YOLO-Modells vor?
Was muss ich bei der Installation von YOLO v8 beachten?
Wie trainiere ich mein KI-Modell?
Wie führe ich mein Modell nach dem Training aus?
1. Welche Hardware verwende ich für die Objekterkennung?
Das hängt von der Architektur des KI-Modells ab, das Sie nutzen möchten. Dieses beeinflusst wesentlich, welche Hardware Sie verwenden und welche Bildrate Sie erzielen können. Manche KI-Modelle lassen sich nicht auf handelsüblicher Hardware ausführen. Ihr YOLO-Modell können Sie aber auf Handychips und CPUs ausführen. Die Modelle verarbeiten Ihre Bilder in wenigen Millisekunden. Andere KI-Modelle benötigen dagegen mehrere Sekunden für die Verarbeitung eines Bildes.
Die Erkennungsgüte ist dabei für die meisten Anwendungen ausreichend. Auch innerhalb einer YOLO-Variante gibt es entsprechend größere Modellarchitekturen, falls Sie eine besonders hohe Erkennungsgüte benötigen. Mittlerweile sind viele YOLO-Varianten von verschiedenen Entwicklerteams verfügbar. Wir konzentrieren uns auf die neuste Veröffentlichung des Entwicklerteams von Ultralytics – YOLO v8. Nachfolgend erklären wir Ihnen, wie Sie die Bilddaten für das Training eines YOLO v8-Modells vorbereiten müssen. Sie lernen auch, wie Sie das Modell im Anschluss trainieren und ausführen.
2. Wie bereite ich die Daten für das Training meines YOLO-Modells vor?
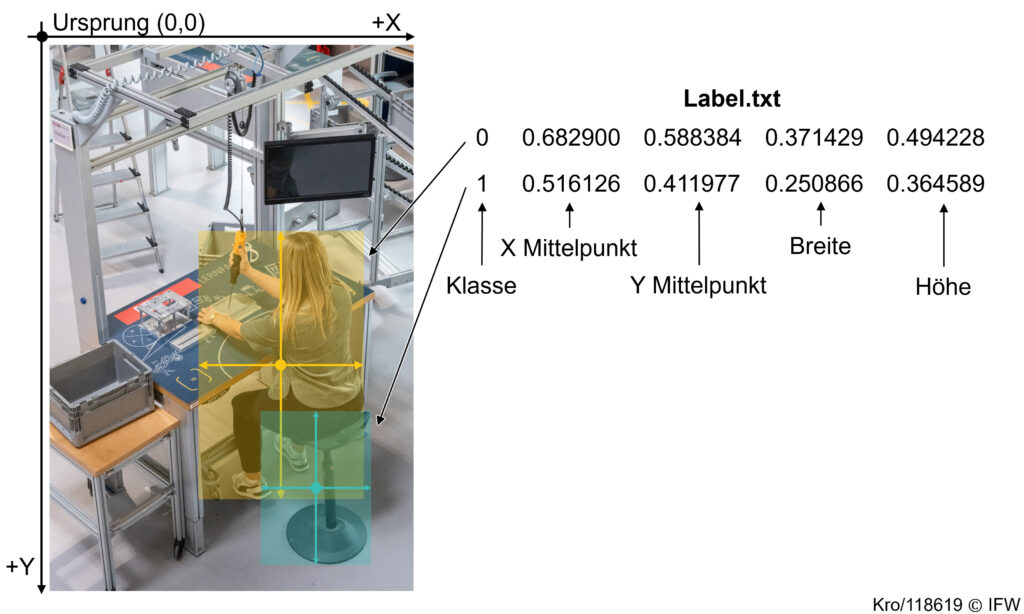
Die Bilddaten müssen bei der Objekterkennung mit Rechtecken, sogenannten Bounding Boxen, und der jeweiligen Klasse gelabelt sein. Das Labelling Ihrer Daten funktioniert so: Die Bounding Box wird durch die X- und Y-Koordinate des Objektmittelpunkts sowie durch die Breite und Höhe beschrieben. Außerdem wird die Angabe normiert. Das heißt, der Wert wird durch die Pixelanzahl der Bildbreite oder -höhe geteilt, sodass ein Wert <= 1 angegeben wird. Ein Beispiel ist in der nachfolgenden Abbildung 1 dargestellt.
Abbildung 1: Beispiellabel für die Objekterkennung
In Abbildung 1 werden die werden die Klassen Person (Klasse 0) und Stuhl (Klasse 1) gelabelt. Wichtig! Die Nummerierung der Klassen beginnt bei null. Jede Zeile beschreibt ein Label. Angegeben werden in einer Zeile:
die Klasse,
die X- und Y-Werte für den Mittelpunkt der Bounding Box und
die Höhe und Breite.
Einfache Labeltools sind beispielsweise Label-Studio, Labelme oder CVAT. Mit diesen Tools können Sie Ihre Bilder sehr einfach labeln. Als Faustregel gilt, dass für ein robustes und generalisiertes Modell circa 1000 Bilder pro Klasse vorliegen sollten. Für einfache Anwendungsfälle reichen oft auch weniger Bilder. Mit Label-Studio lassen sich die Labels direkt im oben gezeigten YOLO-Format exportieren. Bei anderen Tools ist teilweise eine Konvertierung notwendig. Über die Google-Suche finden Sie aber diverse Skripte für die Konvertierung zwischen verschiedenen Labelformaten.
Sie sollten Ihre Bilder und die dazugehörigen Labels noch in Trainings-, Validierungs- und Testdaten aufteilen. Wir empfehlen Ihnen eine Unterteilung in 80 % Trainings-, 10 % Validierungs- und 10 % Testdaten. Der Trainingsdatensatz wird zum Training des KI-Modells genutzt. Bei einigen KI-Modellen – auch bei YOLO v8 – werden Trainingsparameter anhand von Zwischenergebnissen auf dem Validierungsdatensatz angepasst. Mit dem Testdatensatz kann nach Abschluss des Trainings das Modell anhand eines vollkommen unbekannten und neutralen Datensatzes getestet werden. Die Testdaten haben somit keinen Einfluss auf das Training.
YOLO v8 ist hinsichtlich der Datenablage relativ flexibel. Am besten legen Sie Ihre Bilder in den Ordnern Training, Validierung und Test ab. Die Labels können gemeinsam mit Ihren Bilddaten abgelegt werden. Alternativ können Sie in den jeweiligen Ordnern auch noch die Unterordner Images und Labels anlegen. Dann können Sie Ihre Bild- und Labeldaten getrennt voneinander ablegen.
3. Was muss ich bei der Installation von YOLO v8 beachten?
YOLO v8 ist Open Source als Python Code verfügbar und verwendet PyTorch als Framework (wie alle YOLO-Varianten ab Version 4). Mit dieser Bibliothek wird das KI-Modell beschrieben. Sie legt auch die Umgebung für das Training und die Ausführung des KI-Modells fest. Sie können alle notwendigen Bibliotheken über das pip-Paket ultralytics mit diesem Befehl installieren:
pip3 install ultralytics
Den Befehl geben Sie im Terminal (Konsole) ein. Anschließend werden alle benötigten Bibliotheken wie PyTorch, Numpy, etc. installiert. Danach müssen Sie dem Modell Ihren Datensatz übergeben. Hierfür erstellen Sie eine YAML-Datei. In dieser geben Sie den Pfad zum Datensatz sowie die Klassen an. Die Datei können Sie mit einem klassischen Texteditor erstellen. Speichern Sie die Datei als YAML-Datei. Hierfür ändern Sie einfach das „.txt“ in ein „.yaml“. Die Datei sieht dann beispielsweise so aus:
train: /users/proki/yolov8/datasets/yourData/train# 80 % der Bilder
val:/users/proki/yolov8/datasets/yourData/val# 10 % der Bilder
test:/users/proki/yolov8/datasets/yourData/test # 10 % der Bilder
# Classes
names:
0: Person
1: Stuhl
Wichtig: Die Nummerierung der Klassen startet bei 0. Halten Sie auch die Reihenfolge der Klassen ein, die Sie beim Labeln verwendet haben.
YOLO v8 gibt es in unterschiedlichen Größen. YOLO v8s (small) ist vergleichsweise schnell in der Ausführung und erzielt oft bereits gute Ergebnisse. Mit einem größeren Modell lässt sich die Erkennungsgüte steigern. Die Geschwindigkeit nimmt dabei allerdings ab.
4. Objekterkennung mit YOLO v8 – Wie trainiere ich mein Modell?
Wir trainieren nun für 200 Epochen ein vortrainiertes YOLO-v8s-Modell auf der GPU (device=0). Voraussetzung dafür ist eine NVIDIA-Grafikkarte. Haben Sie keine, lassen Sie „device=0“ als Argument weg. Ihr Modell wird dann auf der CPU trainiert. Dabei wird ein vortrainiertes Modell wird. Dieses hat bereits auf einem großes Datensatz gelernt, welche Features aus dem Bild extrahiert werden müssen, um zuverlässig das Objekt zu erkennen und die Position im Bild zu bestimmen. Neu erlernt werden nur die spezifischen Merkmale und Klassen Ihres Datensatzes. Das Training geht so schneller und die Erkennungsgüte des Modells wird in der Regel erhöht.
Nach dem Training wird das KI-Modell automatisch gespeichert. Hier ein Beispiel-Pfad:
Sie können das Modell im Anschluss verwenden, ohne das Training erneut durchführen zu müssen. Mit dem folgenden Befehl können Sie das Modell noch auf dem Testdatensatz testen.
yolo detect val model=/users/proki/yolov8/runs/detect/Erster_Trainingsversuch/weights/best.pt data=/users/proki/yolov8/data/yourData.yaml split=test
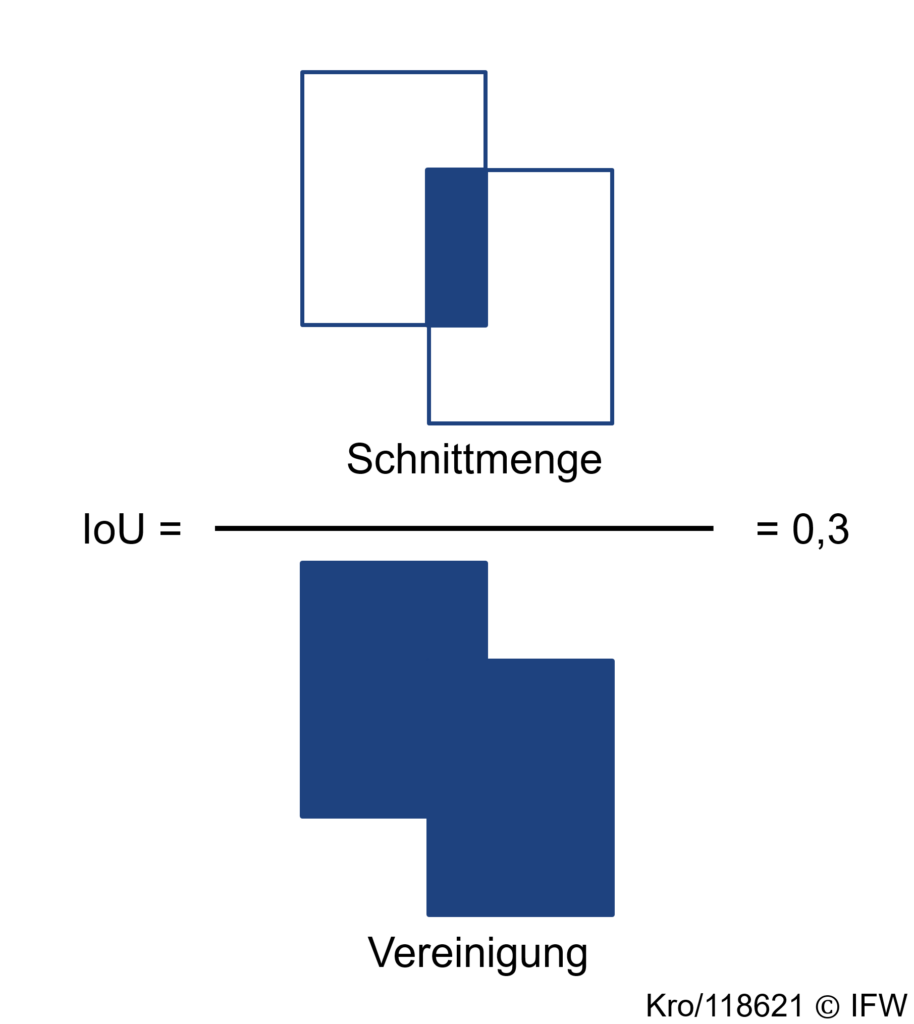
Automatisch ausgegeben werden die mAP@0.5 und die mAP@0.5:0.95. Diese beiden Metriken werden üblicherweise für die Beurteilung der Erkennungsgüte verwendet. Bei der mAP@0.5 wird eine Vorhersage des Modells als wahr bewertet, wenn die Intersection over Union (IoU) (siehe Abbildung 2) zwischen der Vorhergesagten Bounding Box und dem Ground Truth (Label) höher als 0,5 ist. Die IoU beschreibt die Überlappung der vorhergesagten Bounding Box und der Bounding Box des Labels geteilt durch deren vereinigte Fläche. Die mAP@0.5:0.95 ist etwas strenger und berechnet einen Mittelwert für die IOU in Zehnerschritten von 50 % – 95 %.
Abbildung 2: Intersection over Union (IOU)
5. Wie führe ich mein Modell nach dem Training aus?
Sie wissen jetzt, wie gut Ihr KI-Modell auf dem Testdatensatz performt. Um das gespeicherte Modell mit weiteren Daten oder einer anderen Quelle – zum Beispiel einer Kamera – zu testen, verwenden Sie:
0 # Webcam
img.jpg # Image
vid.mp4 # Video
screen # Screenshot
path/ # Ganzer Ordner
list.txt # List of images
list.streams # List of streams
'path/*.jpg' # Alle Bilder in einem Ordner
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Das ging Ihnen zu schnell? In unserer Online-Schulung „Computer Vision anwenden“ gehen wir alle Schritte gemeinsam mit Ihnen durch. Melden Sie sich über unseren Veranstaltungskalender für die nächste Schulung!
ProKI-Hannover nutzt die Klassifizierung und Objekterkennung im Demonstrator für die automatisierte Oberflächenprüfung. Die Segmentierung verwenden wir bei der kamerabasierten Verschleißerkennung. Gerne können Sie sich die Demonstratoren auch direkt bei uns am Produktionstechnischen Zentrum Hannover anschauen.